DeepSeek V4 Flash and Gemini 1.5 Flash represent the leading edge of high-throughput, cost-effective LLMs, both supporting massive 1-million-token context windows. DeepSeek V4 Flash, a 284B MoE architecture released in April 2026, focuses on efficient inference while maintaining reasoning performance that competes with significantly larger proprietary models. Its architecture, featuring a hybrid attention mechanism (CSA + HCA), is optimized specifically for rapid agentic tasks and coding workflows where low latency is critical for developers.
Gemini 1.5 Flash remains Google’s primary offering for high-volume, multimodal-native applications. It excels in integration within the broader Google Cloud ecosystem and provides robust support for diverse data inputs, including native audio and video processing. While both models are positioned as high-efficiency choices, the selection typically hinges on whether your infrastructure requires open-weight portability (DeepSeek) or deep multimodal integration and mature enterprise support (Gemini).
Visual comparison
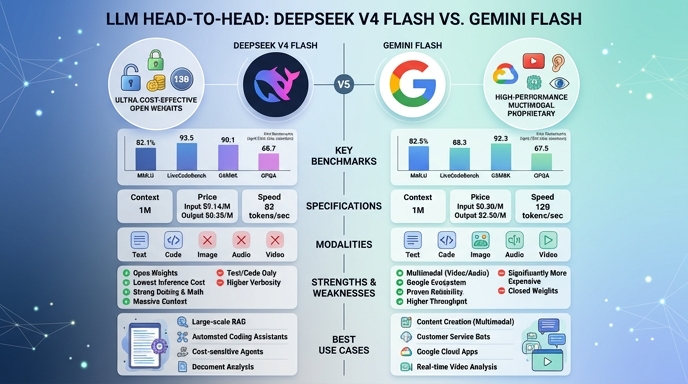
Click to view full size
Benchmark scores
Higher is better
Strengths and weaknesses
When to use each model
Choose DeepSeek V4 Flash when your development requirements prioritize cost-efficiency, self-hosting flexibility, or when deploying on-premise solutions that require an open-weights architecture. It is particularly well-suited for high-throughput coding assistants, agentic workflows, and applications where you need to optimize inference tokens without sacrificing significant reasoning capability.
Choose Gemini 1.5 Flash when your project demands native multimodal ingestion, such as analyzing video files, audio streams, or complex image datasets alongside text. It is the superior choice for enterprise teams already embedded within the Google Cloud ecosystem, where native managed services, integrated security, and existing data pipelines are crucial for rapid time-to-market.
Ready to build?
Try both models on Select
One API key. Intelligent routing. DeepSeek V4 Flash and Gemini Flash available now.
Open Select →Pay as you go. No subscription required.