DeepSeek V4 Flash and Kimi K2.6 represent the latest shift in open-weights efficiency, prioritizing task-specific performance over brute-force scaling. DeepSeek V4 Flash (284B parameters, 13B active) is designed primarily for high-throughput, low-latency applications, utilizing a massive 1M context window that makes it a strong contender for long-context RAG pipelines and rapid data processing. Its architecture favors speed, making it an economical choice for production-grade, repetitive high-volume tasks.
Kimi K2.6 (1T total parameters, 32B active) takes a different approach, positioning itself as a native multimodal agentic model. Built specifically for long-horizon autonomous execution and swarm orchestration, K2.6 excels at complex multi-step tasks where the model must interleave reasoning, tool use, and verification. While it operates within a smaller 262K context window compared to the V4 Flash, its specialization in agent-based coding workflows and tool-calling reliability makes it a superior choice for building autonomous development agents.
Visual comparison
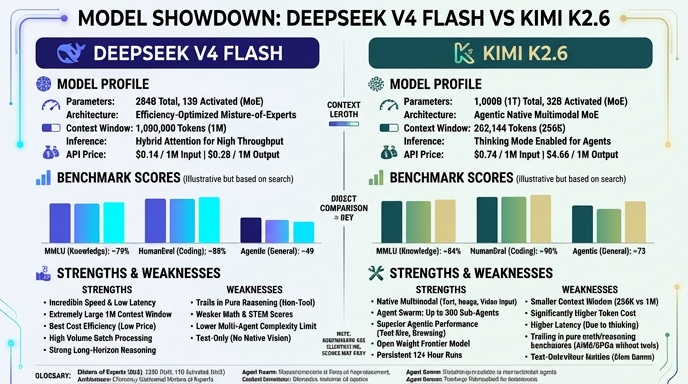
Click to view full size
Video comparison
Benchmark scores
Higher is better
Strengths and weaknesses
When to use each model
Choose DeepSeek V4 Flash for high-volume, latency-sensitive pipelines where broad context is essential. It is the ideal engine for document summarization, large-scale data extraction, and rapid RAG applications where cost-per-request is a primary metric. Its 1M token context window ensures you can process entire codebases or research repositories without needing complex chunking strategies.
Choose Kimi K2.6 when building agentic systems that require autonomous planning and tool execution. It is the preferred model for engineering tasks such as building software agents, managing long-running CI/CD automation, and complex code refactoring, where the model needs to maintain state and context across hundreds of multi-step tool calls and reflections.
Ready to build?
Try both models on Select
One API key. Intelligent routing. DeepSeek V4 Flash and Kimi K2.6 available now.
Open Select →Pay as you go. No subscription required.