DeepSeek V4 Flash and Llama 4 represent two distinct philosophies in the current open-weights landscape. Released in April 2026, DeepSeek V4 Flash is a high-efficiency model optimized for high-volume, low-latency pipelines, leveraging a 284B parameter architecture with only 13B active parameters to balance throughput with reasoning depth. It targets production workloads where cost-per-token and context handling are critical, offering a native 1 million token window that simplifies complex RAG and agentic workflows.
Meta's Llama 4 (specifically the Maverick variant), released in April 2025, established itself as a benchmark-setting open-weights series built on a mixture-of-experts architecture. While slightly older by the fast-moving standards of 2026, it remains a heavily utilized, reliable foundation for multimodal tasks and ecosystem integration. Developers choosing between these models are essentially weighing the aggressive, efficiency-first architectural optimizations of DeepSeek's 2026 release against the proven, broad-utility support of the mature Llama 4 ecosystem.
Visual comparison
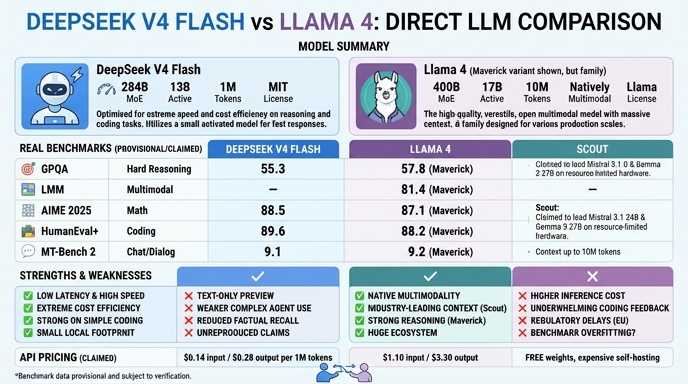
Click to view full size
Benchmark scores
Higher is better
Strengths and weaknesses
When to use each model
Choose DeepSeek V4 Flash when your primary requirements are low-latency, high-volume production pipelines where inference cost is a critical constraint. It is ideal for agentic coding assistants, RAG applications involving massive documentation, and scenarios where you need to process large code repositories in a single context window without triggering chunking overheads.
Choose Llama 4 when you require a stable, battle-tested multimodal model with widespread community support and robust tooling availability. It remains a reliable choice for existing projects already integrated into the Llama ecosystem, or for applications where native image-and-text processing is a primary functional requirement for the end-user experience.
Ready to build?
Try both models on Select
One API key. Intelligent routing. DeepSeek V4 Flash and Llama 4 available now.
Open Select →Pay as you go. No subscription required.