DeepSeek V4 Flash and Mistral Large represent two distinct approaches to large language model deployment. DeepSeek V4 Flash, released in April 2026, is an efficiency-focused Mixture-of-Experts (MoE) model built primarily for high-throughput, cost-sensitive pipelines. It utilizes a hybrid attention architecture to support a 1-million-token context window, making it suitable for processing entire codebases or long document streams at a significantly lower operational cost compared to frontier-class models.
Visual comparison
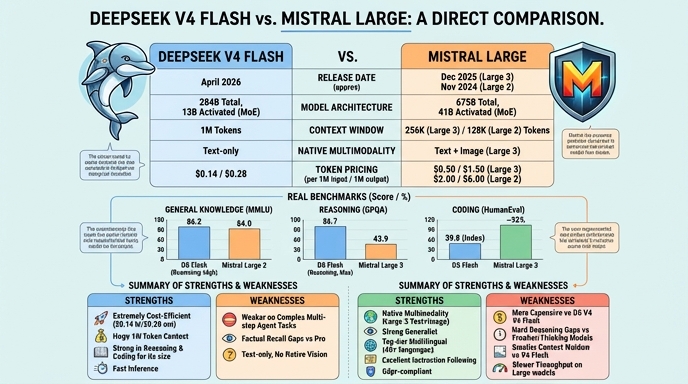
Click to view full size
Benchmark scores
Higher is better
Strengths and weaknesses
When to use each model
Choose DeepSeek V4 Flash for high-throughput, cost-sensitive applications such as large-scale document analysis, log processing, or agentic coding pipelines where you can implement retry or iterative feedback loops to mitigate hallucinations. It is ideal when you need to ingest very long context (up to 1M tokens) without incurring the prohibitive costs associated with frontier-level flagship models.
Choose Mistral Large for enterprise-grade applications where reliability, precision, and multilingual support are primary requirements. It is best suited for complex reasoning, standardized programming tasks, and workflows requiring stable, high-quality outputs where the 128k context window is sufficient. Its proven track record makes it a safer choice for critical business logic where the high hallucination risk of newer, flash-tier models is unacceptable.
Ready to build?
Try both models on Select
One API key. Intelligent routing. DeepSeek V4 Flash and Mistral Large available now.
Open Select →Pay as you go. No subscription required.