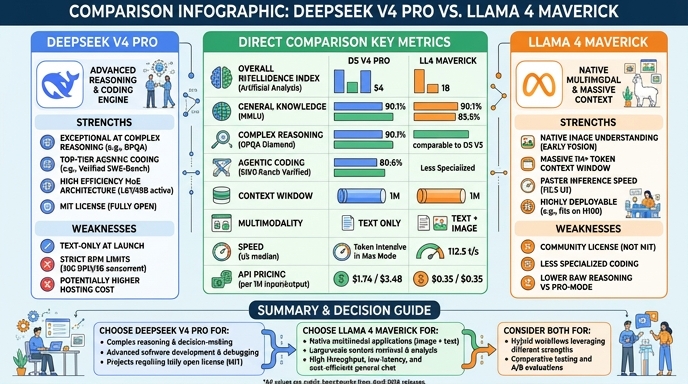
DeepSeek V4 Pro and Llama 4 Maverick represent distinct approaches to the current generation of large language models. DeepSeek V4 Pro leverages a massive Mixture-of-Experts architecture with 1.6 trillion total parameters, optimized for deep reasoning and complex, multi-step agentic workflows. Its hybrid attention architecture allows for efficient processing of 1 million token context windows, making it particularly suited for deep codebase analysis and enterprise-grade reasoning tasks where high-precision output is required.
Llama 4 Maverick takes a different path, focusing on high-efficiency, natively multimodal performance using a 17 billion active parameter MoE structure. It is designed for fast, responsive applications that require broad multimodal understanding—such as image-to-text or visual reasoning—alongside traditional language tasks. While it operates on a different scale than the massive V4 Pro, Maverick excels in latency-sensitive environments and provides a strong performance-to-cost ratio for developers building agile, production-ready AI applications.
Visual comparison
Click to view full size
Benchmark scores
Higher is better
Strengths and weaknesses
When to use each model
Choose DeepSeek V4 Pro when your project demands high-precision, multi-step reasoning or agentic coding capabilities. It is the optimal choice for backend-heavy applications, complex data analysis, or deep-diving into entire repositories where its large context window and superior reasoning accuracy provide a distinct advantage over smaller, more general-purpose models.
Choose Llama 4 Maverick for applications where speed, latency, and multimodal input are critical. It is the ideal selection for building interactive agents, visual reasoning tools, or applications where you need rapid response times across a wide range of text and image tasks, particularly in environments where operational efficiency and cost management are the primary drivers.
Ready to build?
Try both models on Select
One API key. Intelligent routing. DeepSeek V4 Pro and Llama 4 Maverick available now.
Open Select →Pay as you go. No subscription required.