DeepSeek V4 Pro and Mistral Large 3 represent two distinct philosophies in large language model development. DeepSeek V4 Pro, released in April 2026, emphasizes massive context windows and highly specialized mixture-of-experts architectures designed for long-running agentic workflows. It is engineered to handle massive codebases and complex reasoning tasks natively within its 1M token context, positioning itself as a high-throughput, research-forward model for developers building sophisticated autonomous agents.
Mistral Large 3, by contrast, continues Mistral's tradition of reliable, production-ready open-weights deployment. While its 256K context window is smaller than DeepSeek's, it offers consistent performance in enterprise environments where reliability, compliance, and predictable instruction following are prioritized. For developers, the choice often comes down to the specific needs of their architecture: DeepSeek for large-scale, long-context exploration, or Mistral for stable, efficient production integration.
Visual comparison
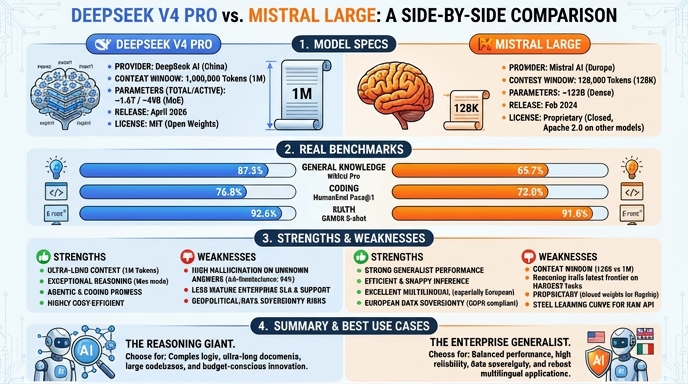
Click to view full size
Benchmark scores
Higher is better
Strengths and weaknesses
When to use each model
Choose DeepSeek V4 Pro if you are building autonomous AI agents that require long-term memory or need to ingest entire code repositories as a single context. It is the superior choice for research-heavy workloads, complex data analysis, and any application where the model must synthesize information across thousands of documents without relying on fragile, chunk-heavy RAG pipelines.
Choose Mistral Large 3 for production-grade applications where stability, predictable output formats, and strict adherence to instruction sets are paramount. It is the ideal workhorse for customer-facing chatbots, standard enterprise automation, and systems requiring high-reliability integration with existing CI/CD or compliance frameworks where the massive context overhead of other models is unnecessary.
Ready to build?
Try both models on Select
One API key. Intelligent routing. DeepSeek V4 Pro and Mistral Large available now.
Open Select →Pay as you go. No subscription required.