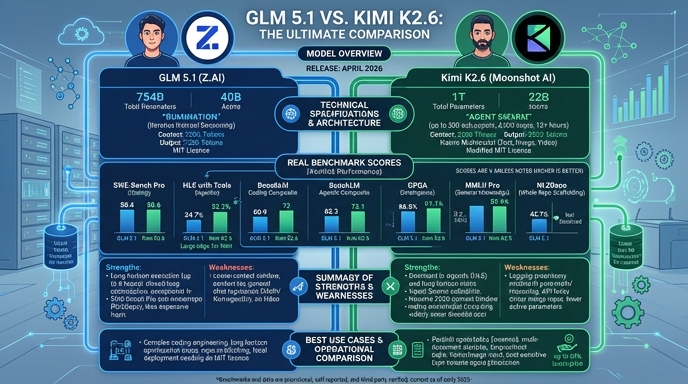
GLM 5.1 and Kimi K2.6 represent the current frontier of open-weights models, both released in April 2026 with a strong emphasis on autonomous agentic workflows and long-horizon software engineering. Developed by Zhipu AI and Moonshot AI respectively, these models leverage Mixture-of-Experts (MoE) architectures to provide high-performance reasoning at lower inference costs than dense equivalents. For developers, the choice between them often centers on specific implementation needs: GLM 5.1 focuses on iterative 'rumination' to solve complex coding tasks, while Kimi K2.6 prioritizes agent swarm orchestration and multi-modal integration for end-to-end autonomous execution.
Both models mark a significant shift toward production-grade, self-directed AI systems that go beyond simple code generation. While both perform exceptionally well on benchmarks like SWE-Bench Pro, their underlying approaches to task decomposition and tool usage differ. GLM 5.1 is highly regarded for its sustained execution in deep-reasoning coding environments, whereas Kimi K2.6 is specifically engineered to coordinate parallel sub-agents, making it a robust candidate for complex, multi-file application development and system-wide refactoring.
Visual comparison
Click to view full size
Benchmark scores
Higher is better
Strengths and weaknesses
When to use each model
Choose GLM 5.1 when your primary requirement is complex, deep-reasoning software engineering tasks where the model needs to think, test, and iteratively refine code over long durations. It is particularly effective for backend systems engineering, where its ability to perform high-level architectural reasoning and prolonged optimization loops provides a distinct advantage in building robust, performant code.
Ready to build?
Try both models on Select
One API key. Intelligent routing. GLM 5.1 and Kimi K2.6 available now.
Open Select →Pay as you go. No subscription required.