Kimi K2.5 and DeepSeek V4 Pro represent the cutting edge of the 2026 open-weights model landscape, designed to compete directly with frontier proprietary systems. Kimi K2.5, developed by Moonshot AI, utilizes a 1-trillion parameter Mixture-of-Experts architecture that prioritizes efficiency and rapid agentic workflows, making it a highly effective tool for developers needing a balance of reasoning depth and fast inference latency. It is particularly noted for its native multimodal capabilities and specialized agentic orchestration.
DeepSeek V4 Pro takes a different approach, scaling to 1.6 trillion total parameters with a massive 1-million token context window. Its architecture is specifically optimized for high-complexity software engineering and long-context retrieval, often outperforming or matching frontier models in coding-heavy tasks. For developers, the choice between these two largely depends on whether the workload prioritizes ultra-long-context analysis or rapid, agent-driven automation.
Visual comparison
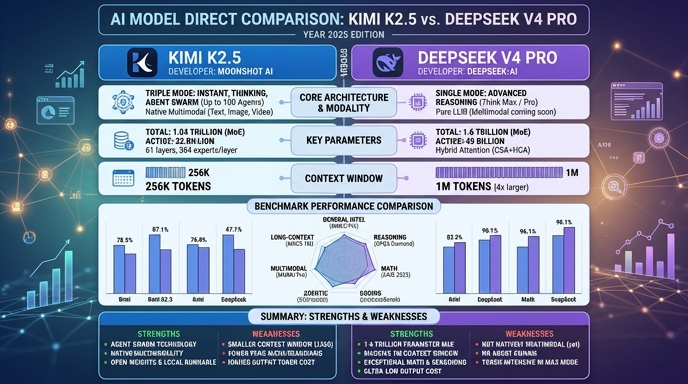
Click to view full size
Benchmark scores
Higher is better
Strengths and weaknesses
When to use each model
Choose Kimi K2.5 when your primary objective is building highly interactive, agentic applications where latency and cost-efficiency are critical. Its architecture excels at workflows that require parallel execution of smaller tasks and visual input processing, making it an ideal candidate for UI automation, RAG pipelines that operate on shorter document chunks, and general-purpose backend services that require rapid, reliable responses without the overhead of massive context loading.
Choose DeepSeek V4 Pro for complex, compute-heavy engineering projects that necessitate a deep understanding of massive codebases or extensive technical documentation. It is the preferred choice for tasks like end-to-end repository migration, large-scale system debugging, or legal/technical analysis where the model must maintain global coherence across hundreds of thousands of tokens. If your application demands absolute reasoning depth at the expense of slightly higher latency and per-token costs, DeepSeek V4 Pro offers the most robust performance.
Ready to build?
Try both models on Select
One API key. Intelligent routing. Kimi K2.5 and DeepSeek V4 Pro available now.
Open Select →Pay as you go. No subscription required.