Qwen3 Coder Next and DeepSeek V4 Flash represent the current leading edge in specialized AI for software development. Qwen3 Coder Next is an 80B parameter Mixture-of-Experts (MoE) model that optimizes inference efficiency by activating only 3B parameters per token. It is heavily tuned for agentic workflows, repository-level understanding, and high-performance local deployment, making it a favorite for developers seeking to build autonomous coding agents without relying solely on cloud infrastructure.
DeepSeek V4 Flash is a 284B MoE model (13B active) designed to serve as a high-throughput, cost-effective API powerhouse. It distinguishes itself with an expansive 1M-token context window and sophisticated reasoning capabilities that rival larger, closed-source models. While Qwen3 Coder Next excels in local integration and agentic flexibility, DeepSeek V4 Flash is engineered for deep reasoning, complex multi-file architectural planning, and massive document analysis where memory and scale are critical.
Visual comparison
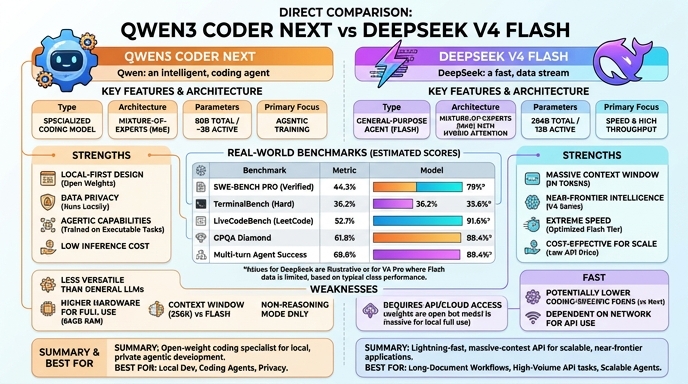
Click to view full size
Benchmark scores
Higher is better
Strengths and weaknesses
When to use each model
Choose Qwen3 Coder Next if you are building autonomous AI coding agents that require tight integration with local environments. It is ideal for developers who need to run model instances on their own hardware, prioritize low latency for real-time code completion, or operate in high-security environments where data privacy requires that code never leaves the local machine. Its architecture is purpose-built to handle recursive agentic tasks, such as automated bug fixing and test generation, with high efficiency.
Choose DeepSeek V4 Flash when your project demands extensive context analysis or high-level architectural reasoning. It is best suited for scenarios where you need to ingest massive documentation, analyze legacy monolithic codebases, or plan complex features that require cross-file dependencies. If you are developing an enterprise-grade application that relies on scalable API calls rather than local inference, DeepSeek V4 Flash provides a robust, cost-effective balance of performance and intelligence that minimizes the need for infrastructure management.
Ready to build?
Try both models on Select
One API key. Intelligent routing. Qwen3 Coder Next and DeepSeek V4 Flash available now.
Open Select →Pay as you go. No subscription required.